3款开源构建基于语音的LLM应用
发布日期:2024/9/4 12:23:37 浏览量:
1. 一款可本地部署的AI语音工具箱:Easy-Voice-Toolkit
github:
https://github.com/Spr-Aachen/Easy-Voice-Toolkit

一款可本地部署的AI语音工具箱:Easy-Voice-Toolkit
可以用于制作语音助手、语音识别、转换声音等
包含:
1、音频处理:提供音频文件的自动化处理工具
2、语音识别:识别音频中的语音内容
3、语音转录:将语音转换为文本
4、数据集创建:支持SRT格式转换和WAV文件分割
5、模型训练:训练语音模型
6、语音转换:将一种语音转换为另一种语音
Easy-Voice-Toolkit提供了一套完整的语音处理流程,可以根据需要选择使用,也可以按顺序使用,将原始音频文件转换为语音模型
2. 分分钟构建基于语音的 LLM 应用 vocodehq
https://github.com/vocodedev/vocode-core
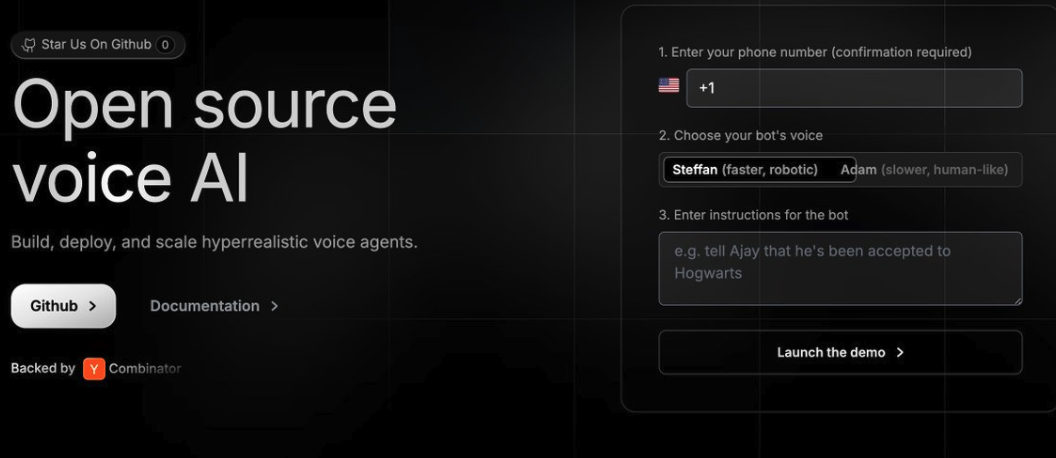
使用 Vocode 可以构建与 LLM 的实时流式对话,并将它们部署到电话通话、Zoom 会议等场景中,还可以构建个人助理或类似语音象棋的应用。主要特性 使用系统音频启动对话 设置一个由基于 LLM Agent 响应的电话号码 从您的电话号码发起由基于 LLM Agent 管理的电话呼叫 拨入 Zoom 通话 在 Langchain Agent中使用向真实电话号码的外呼功能 开箱即用的集成: - 语音转义服务:AssemblyAI、Deepgram、 Gladia、Google Cloud、 Microsoft Azure、RevAI、Whisper - 语音合成服务:http://Rime.ai、Microsoft Azure、Google Cloud、http://Play.ht、Eleven Labs、Cartesia、Coqui (OSS)、gTTS、StreamElements、Bark、AWS Polly
3. 实时对话能力的多模态模型:Mini-Omni ,支持端到端的语音输入、输出
github:https://github.com/gpt-omni/mini-omni
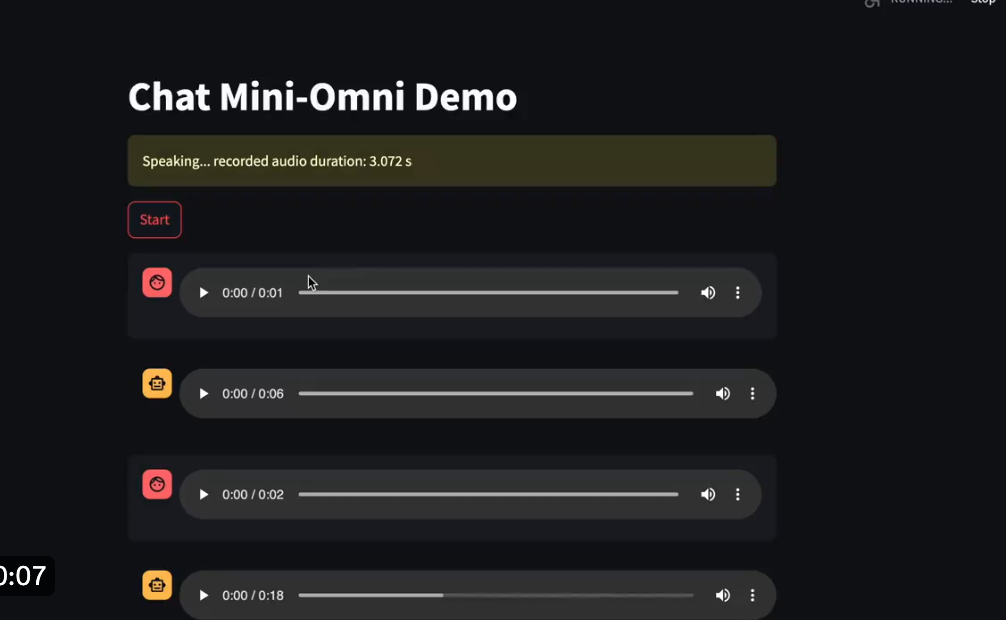
Mini-Omni是清华大学启元实验室开源的项目,能听、能说也能实时思考,在实时语音交互上媲美GPT-4o
特点:
1、实时语音到语音的对话能力: 无需额外的ASR或TTS模型
2、边思考边说话: 能够同时生成文本和音频
3、流式音频输出: 支持流式音频输出
4、"Any Model Can Talk" 方法: Mini-Omni 可以将语音交互能力添加到其他模型中,为其他模型赋能
马上咨询: 如果您有业务方面的问题或者需求,欢迎您咨询!我们带来的不仅仅是技术,还有行业经验积累。
QQ: 39764417/308460098 Phone: 13 9800 1 9844 / 135 6887 9550 联系人:石先生/雷先生