openAI o1 技术点启示
发布日期:2024/9/20 16:44:32 浏览量:
1、思维链
CoT(Chain of thought,思维链),是学者们发现的能够激发大模型通过“思考”来回答困难问题的技术,可以显著提高其在推理等任务上的正确率。这个思路在两年前的几篇经典论文中已经得到不断完善。
《Chain-of-Thought Prompting Elicits Reasoning in Large Language Models,NeurIPS2022》这篇文章提出,在问LLM问题前,手工在prompt里面加入一些包含思维过程(Chain of thought)的问答示例(Manual CoT),就可以让LLM在推理任务上大幅提升。
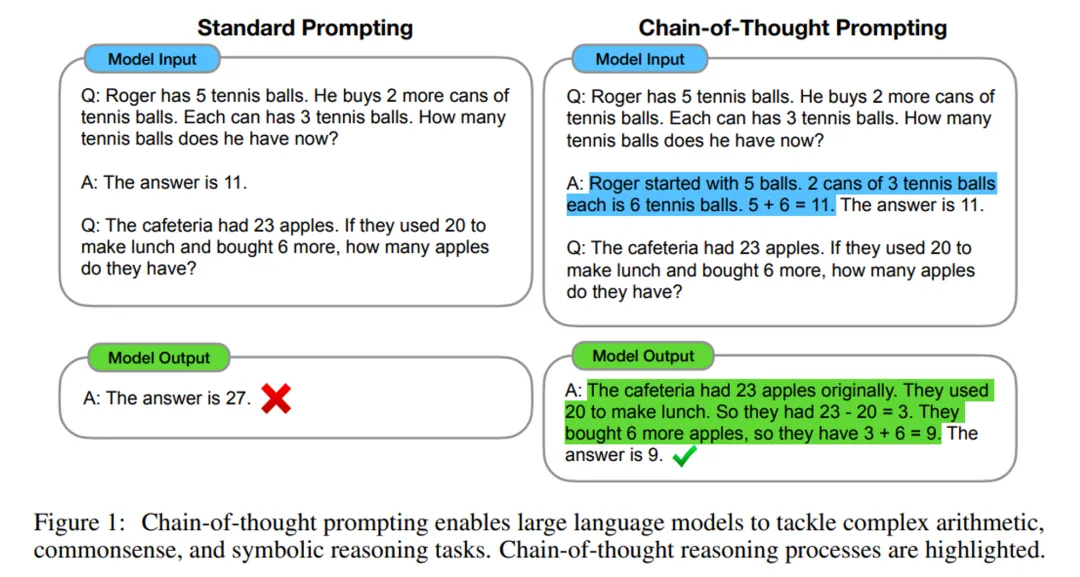
《Large language models are zero-shot reasoners. NeurIPS2022》提出先使用 “Let’s think step by step.” 让模型自己给出推理过程(Zero-shot CoT ),也衍生出诸如“一步一步慢慢来“这些著名的咒语。
 《Automatic Chain of Thought Prompting in Large Language Models,ICLR2023》这篇文章可以理解为二者的结合,先用 “Let’s think step by step.” 咒语产生推理过程,再把这些过程加到prompt里面去引导大模型推理。这样不需要自己写,又能相对靠谱。
《Automatic Chain of Thought Prompting in Large Language Models,ICLR2023》这篇文章可以理解为二者的结合,先用 “Let’s think step by step.” 咒语产生推理过程,再把这些过程加到prompt里面去引导大模型推理。这样不需要自己写,又能相对靠谱。
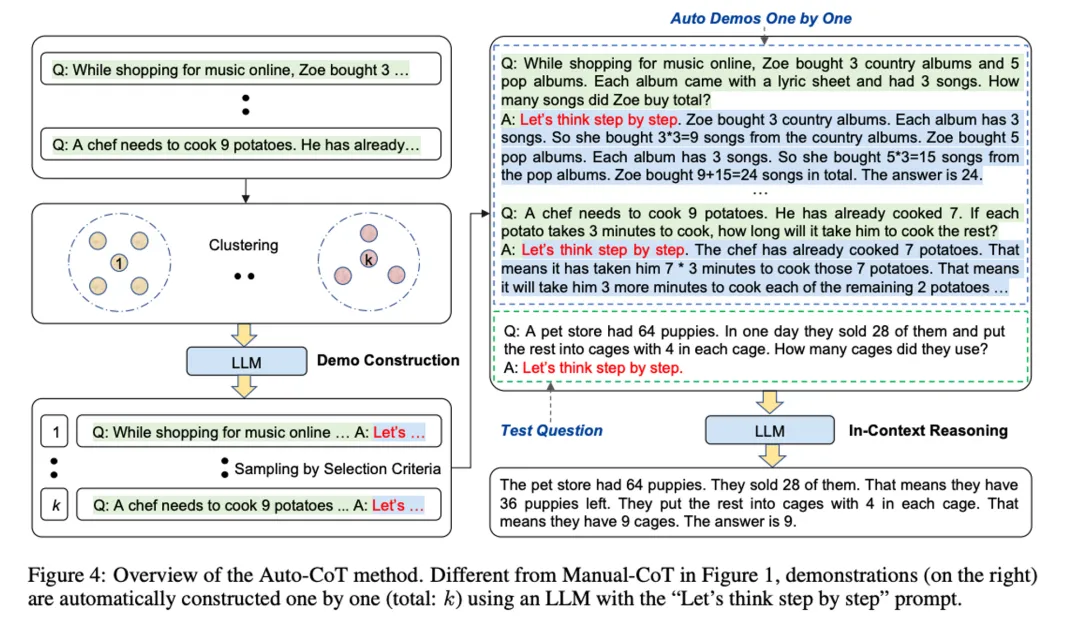
在这些之后,CoT还经历了千变万化的演进,但大都还是通过prompt来诱导大模型分步思维,人们就在想,能不能让大模型自己学会这种方法呢?
2、强化学习和自学推理
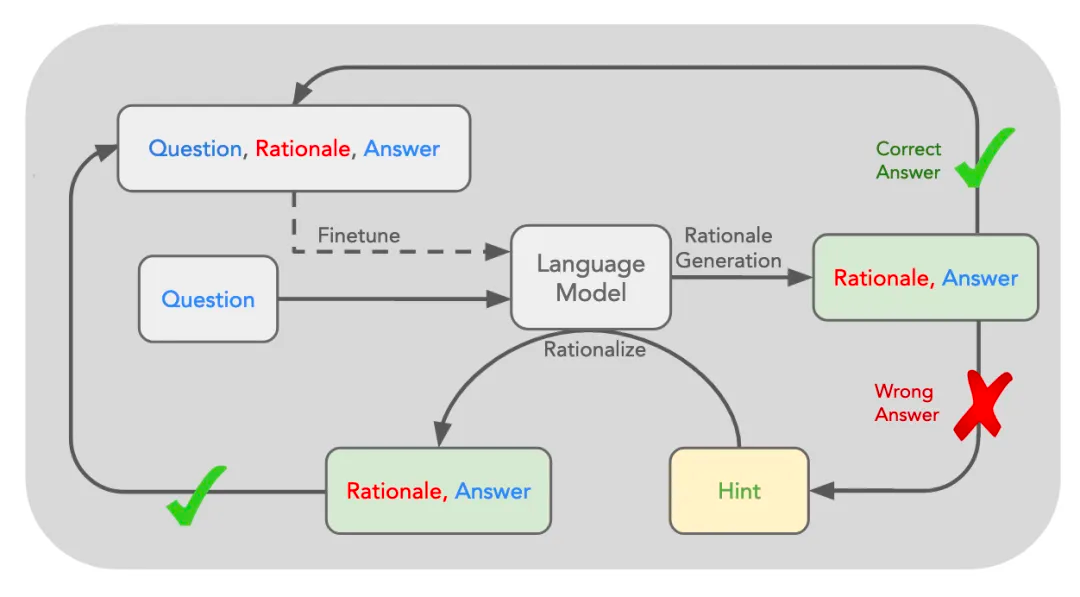
类似当年的Alpha-Zero,强化学习是让机器自己通过与环境交互并观察结果的方式调整行为策略的机器学习方法,但之前很难用于语言模型。直到斯坦福大学 2022 年提出一种「自学推理」(Self-Taught Reasoner,STaR)方法:先给模型一些例题详细解法,再让模型学着去解更多的题,如果做对就把方法再补充到例题里,形成数据集,对原模型微调,让模型学会这些方法,这也是一种经典的自动生成数据的方法。
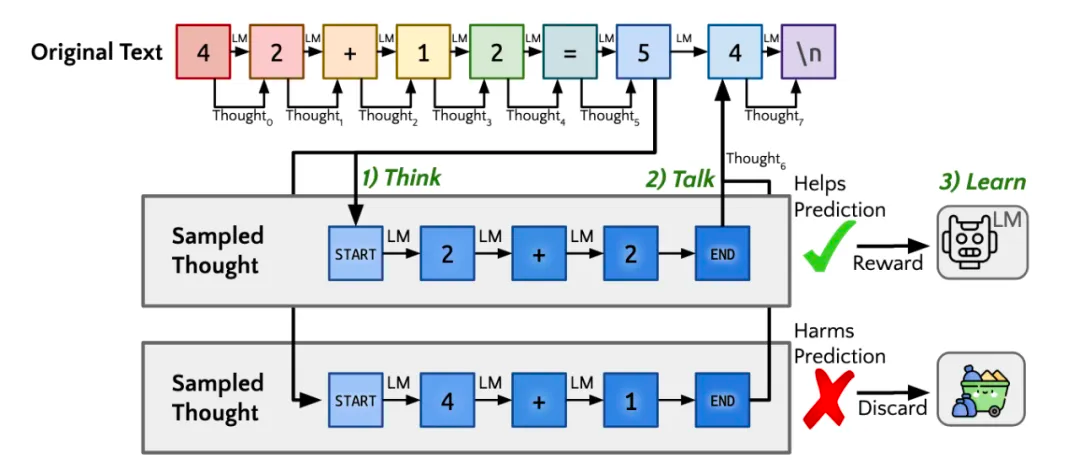
后来基于此又演进出了名为"Quiet-STaR"的新技术,也就是传说中的Q*,翻译过来大概为"安静的自学推理"。核心为在每个输入 token 之后插入一个"思考"步骤,让大模型生成内部推理。然后,系统会评估这些推理是否有助于预测后续文本,并相应地调整模型参数。这种方法允许模型在处理各种文本时都能进行隐含的推理,而不仅仅是在回答问题时。
用人话说呢,加入强化学习就是在大模型训练时就教他一些套路(当然应该也是模型自己生成并优选的),思考时直接就按题型选套路分解问题、按步骤执行、反复审核,不行就换个套路,跟通常教小学生普奥的套路类似。但这种自学习机制,由于奖励模型的复杂,所以通常仅在数学和代码领域表现较好。
3、Scaling Law的延伸
以上技术手段结合的后果就是,预训练阶段并没有什么变化,但在推理阶段的计算量大大增加,原来追求的快思考变成了故意放慢速度,以追求更加准确的结果。
OpenAI 提及了自己训练中发现的一个现象:随着更多的强化学习(训练时计算)和更多的思考时间(推理时计算),o1 的性能能持续提高。

英伟达AI领导者 Jim Fan 在 X 上点评了这一事件的历史意义——模型不仅仅拥有训练时的 scaling law,还拥有推理层面的 scaling law,双曲线的共同增长,将突破之前大模型能力的提升瓶颈。“之前,没人能将 AlphaGo 的成功复制到大模型上,使用更多的计算让模型走向超人的能力。目前,我们已经翻过这一页了。”
可以预见,在预训练边际成本递减的背景下,基于强化学习的推理增强会越来越受到重视并发挥作用,也会有更多的算力被投入到推理阶段,全球人工智能芯片和算力的需求也还会继续增加。
马上咨询: 如果您有业务方面的问题或者需求,欢迎您咨询!我们带来的不仅仅是技术,还有行业经验积累。
QQ: 39764417/308460098 Phone: 13 9800 1 9844 / 135 6887 9550 联系人:石先生/雷先生