腾讯开源超大混元视频生成模型
发布日期:2024/12/3 17:59:31 浏览量:
前段时间腾讯开源了应该是当前最大的 MoE LLM 和强大的 3D 生成模型,本来以为已经够强了,没想到全线开花,今天又会发布了混元视频生成相关模型。
测试了一段时间混元视频生成模型整体效果非常厉害,在美学表现、稳定性、运动幅度的品质上都是一流的,重要的是这个级别的模型还是开源的,直接把一堆二线模型杀穿了,非常期待更多的社区玩法和内容。
今天的主要发布内容有:
-
13B 的开源混元视频生成模型(网页端和 APP)
-
基于说话音频生成对应的人物说话视频项目(待上线)
-
端到端的视频自动配音模型(待上线)
-
面部表情迁移模型(待上线)
模型技术介绍
HunyuanVideo 应该是目前开源模型中参数最多、性能最强的文生视频大模型。它包含130亿参数。
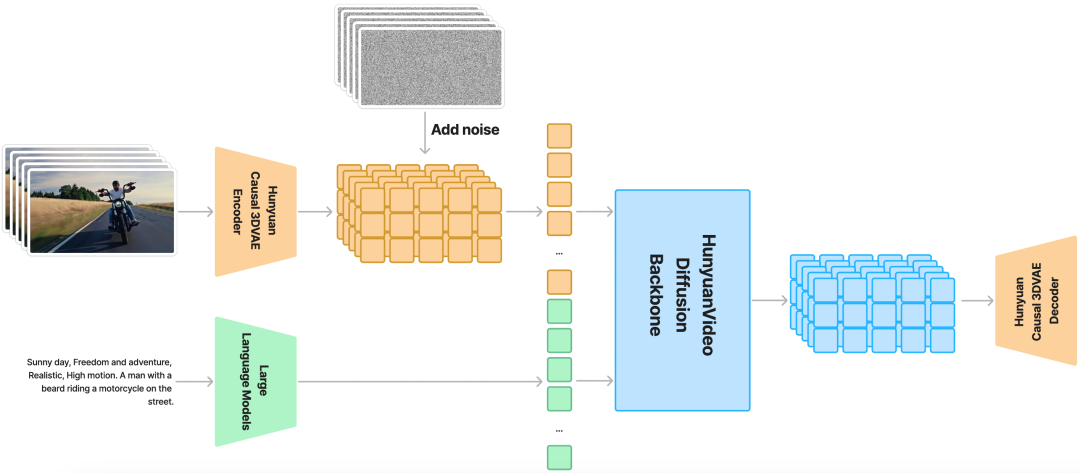
混元视频模型采用了时空压缩的潜在空间设计,通过因果3D变分自编码器进行压缩。模型使用大语言模型编码文本提示作为条件,并结合高斯噪声作为输入来生成潜在表示,最后通过3D变分自编码器解码器生成图像或视频。
在架构上,混元视频模型采用了双流到单流的混合设计。在双流阶段,视频和文本标记分别通过多个Transformer模块独立处理;在单流阶段,将视频和文本标记连接起来进行多模态信息融合。
模型创新地使用了多模态大语言模型作为文本编码器,这种方式相比传统的CLIP和T5-XXL具有更好的图文对齐效果和复杂推理能力。为了增强文本特征,模型还引入了双向token优化器。
在实现细节上,模型使用了3D变分自编码器来压缩视频空间,并提供了两种提示词重写模式:普通模式侧重准确理解用户意图,大师模式则着重提升视觉质量的描述。
如何使用
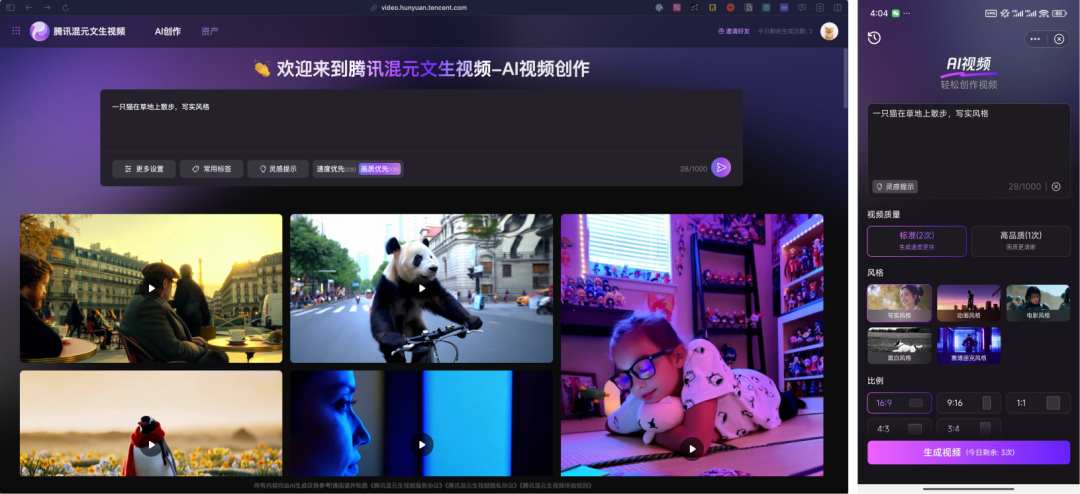
你现在可以在网页端和元宝 APP 的 AI 应用-AI 视频位置在线使用混元视频生成模型,目前只支持文生视频、一个月左右会支持图生视频,而且还是免费的。
官网:https://aivideo.hunyuan.tencent.com
代码:https://github.com/Tencent/HunyuanVideo
模型:https://huggingface.co/tencent/HunyuanVideo
技术报告:https://github.com/Tencent/HunyuanVideo/blob/main/assets/hunyuanvideo.pdf
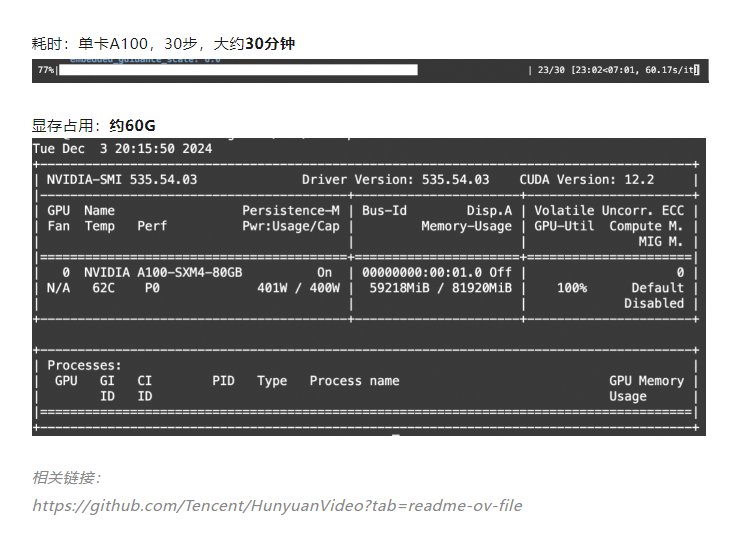
来个大佬的测试数据,5秒视频,显存消耗和需要的时间
马上咨询: 如果您有业务方面的问题或者需求,欢迎您咨询!我们带来的不仅仅是技术,还有行业经验积累。
QQ: 39764417/308460098 Phone: 13 9800 1 9844 / 135 6887 9550 联系人:石先生/雷先生