全AI制作视频流程
发布日期:2023/3/7 21:44:52 浏览量:
---- 本文转自网络,如有侵权请联系我们删除 ----
本文介绍全AI制作视频的过程和工具,以及这项技术背后的神秘世界。通过ChatGPT的散文,Stable Diffusion生成的人物,D-ID合成的人物动态,text-to-speech技术朗诵的文字和AIVA创作的背景音乐。
AI视频制作的发展历程
随着人工智能技术的不断发展,AI视频制作也开始迎来了革命性的变化。早期的视频制作是由人类摄制和编辑的,但这需要大量的时间和人力资源。而如今,AI技术已经可以通过图像识别、自然语言处理、深度学习等技术,完全自动化地完成视频制作过程。
在过去的几年里,AI视频制作已经经历了巨大的变化和发展。例如,视频自动剪辑技术已经可以通过智能算法将大量素材剪辑成短视频,从而极大地提高了视频制作效率。此外,虚拟人物技术的发展也为视频制作提供了更多的可能性,例如利用Stable Diffusion生成虚拟人物,利用D-ID动态合成技术实现虚拟人物的动作效果等。
除此之外,人类工作只有最后将背景音乐和视频合成在一起。而背景音乐也可以通过AI音乐生成技术来自动创作,例如AIVA(Artificial Intelligence Virtual Artist)就是一款由人工智能创作音乐的软件。
总之,随着人工智能技术的发展,AI视频制作将会变得越来越普及和高效。下一步,我们可以期待更多创新的AI技术将会应用于视频制作领域,从而进一步提高视频制作的质量和效率。
本文视频所用的AI工具介绍
1.使用Stable Diffusion生成人物形象
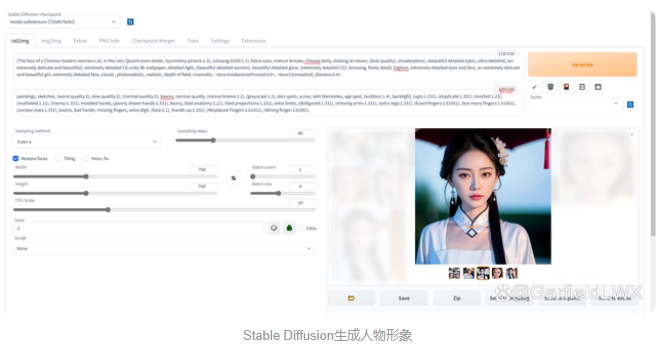
基于Stable Diffusion模型的在线图像生成工具,它可以让用户轻松地通过简单的文本输入生成各种高质量的图像,如风景、动物、人物等。用户只需要输入一段简短的提示文本,就可以生成对应的图像,并可以对生成的图像进行细微的调整,如修改亮度、对比度、颜色等,以获得满意的结果。
Stable Diffusion Web UI的核心是Stable Diffusion模型,它是一种基于随机微分方程的图像生成方法。该模型使用随机微分方程描述图像随时间变化的过程,并通过迭代计算来生成图像。与传统的深度学习模型相比,Stable Diffusion模型不需要预先训练,可以直接从随机噪声开始生成图像,并且可以在迭代的过程中逐步改进图像的质量,生成更加真实、细致的图像。
Stable Diffusion属于开源项目,GitHub上有多种源码可以下载,Hugging Face囊括了几乎现在流行的所有模型。部署方式也很灵活,除本地部署外,也可以在Google Colab、Kaggle等云端部署。感兴趣的朋友可以网上搜索一下,各种安装部署教程相当多。
2.使用ChatGPT写出文章

对于ChatGPT我就不做过多赘述了,但要说的是,因为中文语言的深度学习量不够,生成文章并没有英文那么流畅,这一点我相信不管是ChatGPT也好,还是我们正在进行中国产的自然语言模型也好,随着AI技术的进一步发展,模型的表现肯定会越来越好!
3.使用AIVA生产背景音乐
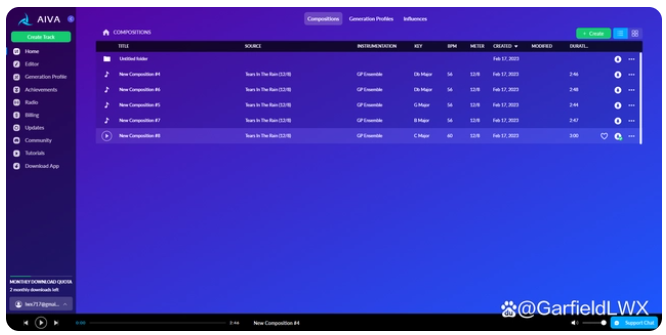
AIVA是一家人工智能音乐制作公司,其核心产品是使用人工智能技术自动生成音乐作品。AIVA的算法通过学习和模仿大量不同风格的音乐,可以自动生成符合用户要求的音乐作品,包括电影音乐、广告音乐、游戏音乐、视频制作音乐等等。
AIVA的音乐制作过程与传统音乐制作方法有所不同。传统的音乐制作需要人类作曲家进行创作、编曲、演奏等多个环节。而AIVA的算法基于机器学习和深度神经网络技术,能够模拟作曲家的思维方式和风格,并自动生成符合用户需求的音乐作品。
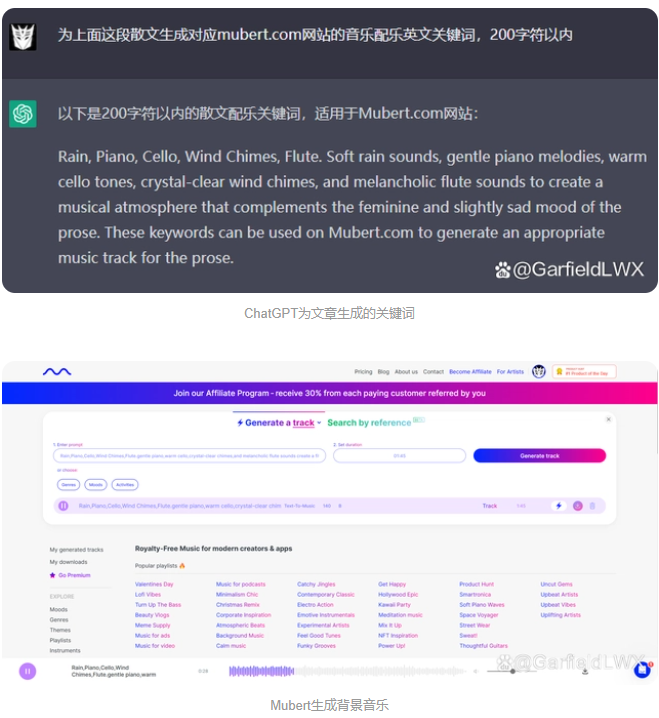
本来打算背影音乐是采用ChatGPT根据文章提供关键词,然后通过关键词在Mubert由人工智能生成背景音乐,但Mubert产出的音乐确实与场景不协调,所以弃用,改用AIVA做了背景音乐。
4.使用Text-to-Speech朗诵文章
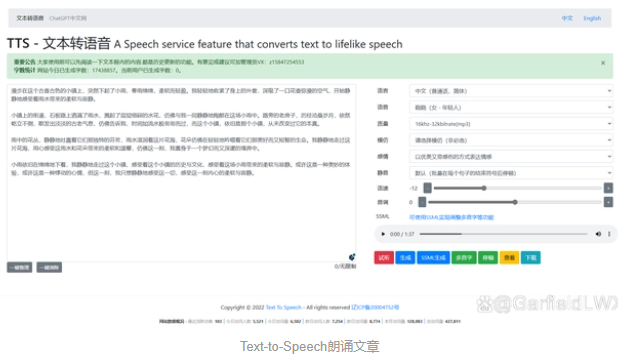
Text-to-Speech技术是一种人工智能技术,它可以将文本转换成自然语言的语音输出。使用这种技术,用户可以将文本转换成音频文件,而不需要用人工的方式进行录音或找到配音演员。
这种技术的实现通常涉及到语音合成和自然语言处理。语音合成是将文本转换成语音的过程,而自然语言处理则是通过对文本进行分析和理解,为合成语音提供正确的语音调、节奏、重音和声音特点等。
目前,Text-to-Speech技术已经在很多领域得到了应用,例如自动语音应答系统、电子书朗读、虚拟助手等。随着人工智能技术的不断发展,这种技术在语音交互和娱乐领域的应用也越来越广泛,例如语音助手、智能音箱、游戏等。
5.使用D-ID生成人物口型动态并合成朗诵
D-ID是一种基于人工智能技术的人脸视频合成技术,能够将一个人的脸替换成其他人的脸,同时保留原始人物的表情、动作和肢体语言等细节。该技术采用了深度学习算法,先对原始视频进行分析,提取出原始人物的面部轮廓、表情、姿态等特征,然后再将目标人物的面部信息与原始人物的特征进行匹配,生成合成后的视频。
D-ID技术可以被应用于电影、电视、广告等领域,使得制片人可以更加灵活地进行人物替换,避免在拍摄中出现的各种限制和问题,同时也可以大大减少后期制作的工作量和成本。此外,D-ID技术还可以用于视频内容的隐私保护,比如模糊敏感区域或者完全替换人物的脸部信息,使得视频中的人物难以被识别。
最后,人工完成的部分,知识用剪辑软件将视频和背景音乐合成。
AI视频制作的优势和挑战
AI视频制作的优势和挑战相互交织,虽然技术的不断发展为我们带来了许多优势,但也面临着一些挑战。
优势:
- 提高效率:相比人工制作,AI视频制作能够自动化处理,缩短了制作时间,提高了制作效率,降低了制作成本。
- 提升质量:AI视频制作依赖于先进的算法和技术,能够在保证视觉效果的前提下,优化视频的内容、剧情、色调等方面,提升视频质量。
- 创新思维:AI视频制作可以产生全新的思路,启发人们在视频制作方面的创新思维,推动视频制作行业向前发展。
挑战:
- 专业技能缺失:AI视频制作需要大量的专业技能支持,包括算法、数据分析、程序开发、视觉艺术等多个领域的知识和技能,而目前市场上的专业人才较为匮乏。
- 数据质量不足:AI视频制作需要大量的数据支撑,而且数据的质量直接影响到视频制作的效果,如果数据不充分、不准确或不完整,就会影响视频的质量。
- 智能化程度不够:虽然AI技术在视频制作方面已经取得了很大进展,但是智能化程度还不够,无法实现完全自动化的制作过程,需要人类的干预和指导。
面对这些挑战,我们需要不断推进AI技术的发展,加强专业人才培养,提高数据质量,提高智能化程度,才能更好地应对AI视频制作的挑战。
马上咨询: 如果您有业务方面的问题或者需求,欢迎您咨询!我们带来的不仅仅是技术,还有行业经验积累。
QQ: 39764417/308460098 Phone: 13 9800 1 9844 / 135 6887 9550 联系人:石先生/雷先生