从产品经理角度解说知识图谱
发布日期:2022/5/5 11:58:16 浏览量:
知识图谱是什么呢?又是怎么构建的?本文作者从知识图谱的应用、构建过程、数据要求等方面进行了分析,希望能给同是非技术出生的产品经理带来帮助。

因为工作中参与了一项智能问答相关的项目,所以我需要了解“知识图谱”的相关知识。作为非技术出身的B端产品经理,初涉AI领域多少有点陌生和不适应。
于是翻阅了很多文献资料及技术科普,也请教了身边做AI的技术同学,从中大致了解了“知识图谱”的一些原理,并整理了以下文章。
希望我的文章能让同是非技术出生的产品经理,或者其他岗位的同学,能更简单、快速地了解什么是“知识图谱”。
一、 知识图谱的应用
在介绍知识图谱前,先说下知识图谱在日常中的应用。
1. 智能搜索
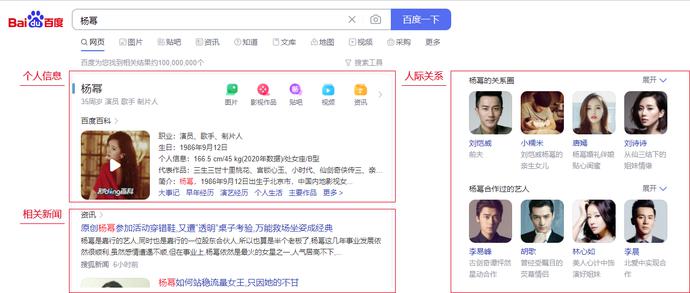
举个例子,你在使用百度搜索“杨幂”时,搜索结果除了包杨幂的个人信息及相关新闻以外,还给你展示了她的关系圈及合作过的艺人,这些人际关系信息都与“杨幂”这个关键字没有重合,但因为和“杨幂”这个实体有实际关系,所以都在“杨幂”的搜索结果中。
2. 智能问答
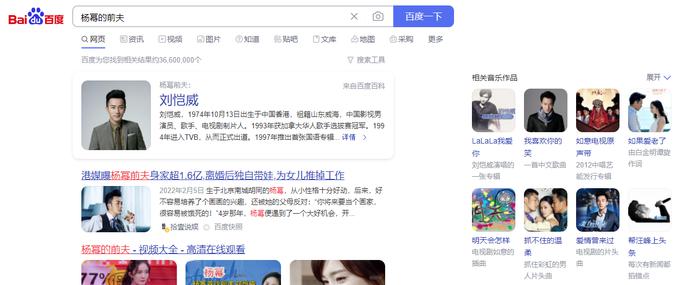
在智能问答方面,会通过知识图谱为你推理出答案。例如,你搜索“杨幂的前夫”,会直接给你返回“刘恺威”的信息。
再举个例子,在线上医疗行业,当患者想挂号却不清楚该挂哪个科室时,可以通过诊前助手获取科室信息。诊前助手是基于专业医疗知识图谱,采用多种算法模型与多轮智能交去互理解病人的病情,根据病人的病情精准匹配就诊科室。
3. 个性化推荐
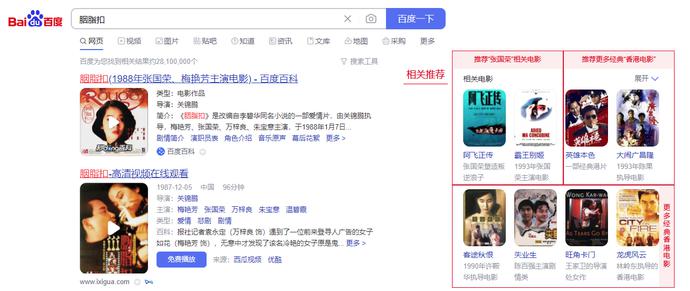
在个性化推荐方面,以搜索张国荣的“胭脂扣”为例,会基于《胭脂扣》的电影信息,如演员、导演、上映年份、作品类型等,推荐出更多关联作品。例如会推荐张国荣的其他电影、推荐同一时期(80-90年代)的香港电影、与张国荣合作过的其他演员的电影等等。
4. 风险防范
以支付宝为例,在支付场景中,用知识图谱将刷单诈骗及信用卡套现等行为扼杀在摇篮中:通过知识图谱的图数据库,对不同的个体、团体做关联分析,从人物在指定时间内的行为,例如去过地方的IP地址、曾经使用过的MAC地址(包括手机端、PC端、WIFI等)、社交网络的关联度分析,银行账号之间是否有历史交易信息等,判断用户是否存在风险行为。
二、知识图谱定义
在描述定义之前,我们先看看知识图谱的表现形式——【E-R图】:

(图片源自百度搜索)
从上图我们可以发现,无论E-R图变换成什么形状,外观如何不同,他都是由多个点和多条线互相连接形成的关系型网络。
点我们称为【实体】,线我们称为【关系】,每个实体可能和一个或多个实体存在关系。基于此,要组成最简单的关系型网络,只需三个要素:两个实体和一个关系。这样的结构,我们称之为“三元组”,多个三元组构成知识图谱。
(三元组)
举个例子:“小芳和小明是同事,因为工作需要,两人都在选购笔记本。小明觉得用苹果笔记本会更有逼格,所以入手了,而小芳觉得Lenovo的笔记本比较便宜,所以选择了Lenovo。后来小芳发现,一直被同事安利的sketch这个软件只在苹果电脑有,它比Axure更智能好用。”从这句话中,我们可以拆解多个三元组:
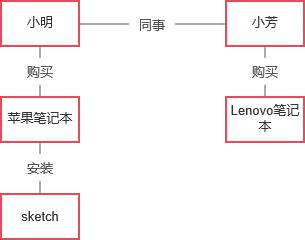
· 实体:小明、小芳、苹果笔记本、Lenovo笔记本、Sketch。实体一般是名词,表示的是人、事、物的抽象化对象。
· 关系:购买、拥有、同事。关系是指两个实体之间的联系,这种联系多种多样,可以是类属关系、并列关系等。
知识图谱的三元组除了可以表达实体间的关系以外,还能表示实体的某种属性。比如“小明”是实体,他的“性别、出生日期、籍贯”等可划为属性。
事物被定义为实体的“属性”,有两条基本准则:
1. 作为属性,不能再具有需要描述的性质。属性必须是不可分的数据项,不能包含其他属性
2. 属性不能与其他实体具有联系
同时值得注意的是,根据实际情况,实体有时可以是属性,属性也可以是实体。
以下图为例:“职工”是一个实体,“职工号、姓名、年龄”是职工的属性,“职称”如果没有与“工资、文位津贴、福利”挂钩,换句话说,没有需要进一步描述的特性,则根据准则 1 可以作为职工实体的属性。
但如果不同的职称有不同的工资、岗位津贴和不同的附加福利,则职称作为一个实体看待就更恰当。
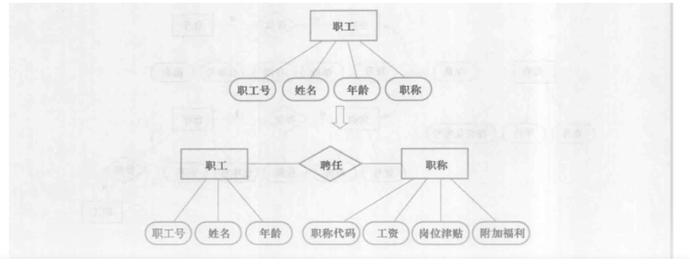
(图片源自网络,如侵权请联系删除)
说到这里,大家应该能更好理解【知识图谱】的定义:知识图谱是结构化语义知识库,用于以符号形式描述物理世界中的概念及其相互关系,其基本组成单位是『实体-关系-实体』三元组,以及实体及其相关属性-值对,实体之间通过关系相互联结,构成网状的知识结构。
知识图谱能能够打破不同场景下的数据隔离,为搜索、推荐、问答、解释与决策等应用提供基础支撑。
三、知识图谱的构建过程
了解知识图谱的构建,能帮助我们更好理解知识图谱的应用原理。
知识图谱的构建流程,总结有三:
1. 信息获取
2. 知识融合
3. 知识加工
对每个步骤的介绍及其意义,我整理了如下表格:

非商业转载请注明出处
下图是知识图谱的技术架构,可以帮助大家更好理解知识图谱的构建流程。其中虚线框内的部分为知识图谱的构建过程,同时也是知识图谱更新的过程。
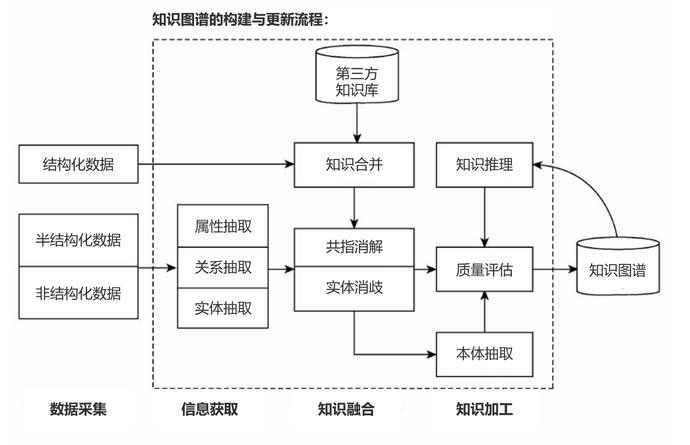
(图片源自网络,已作中文化处理,如侵权请联系删除)
四、数据要求及数据库类型
1)要构建知识图谱,需要怎样的数据呢?
答案是:结构化的数据。
知识图谱的原始数据类型一般来说有三类:结构化数据、非结构化数据、半结构化数据。而最终的知识图谱需要结构化数据作为支撑。
所谓结构化数据,是指高度组织和整齐格式化的数据,它是可以放入电子表格中的数据类型。典型的结构化数据包括:信用卡号码、日期、财务金额、电话号码、地址、产品名称等。
与之相对的非结构化数据是指不容易组织或格式化的数据,它没有预定义的数据模型,不方便用数据库二维逻辑表来表现的数据。它可能是文本的或非文本的,也可能是人为的或机器生成的。
简单来说,非结构化数据就是字段可变的的数据,主要是一些文档、文件等,比如一些合同文件、文章、PDF文档等。
而半结构化数据,是非关系模型的,有基本固定结构模式的数据,例如日志文件、XML 文档、JSON 文档等。
对于非结构化数据及半结构化数据,需要我们确认从中提取哪些可用信息,并制定信息录入规则,借助NLP等技术,将有效信息生成为结构化数据,再计入知识图谱中。
2)图数据库及关系型数据库的差别
知识图谱是用图数据库存储数据的。所谓图数据库,不是指存储图片、图像的数据库,而是指存储图这种数据结构的数据库。之前我们说的E-R图,就是图数据的可视化展示。
不同于传统的使用二维表格存储数据的关系型数据库,图数据库在传统意义上被归类为NoSQL(Not Only SQL)数据库的一种,也就是说图数据库属于非关系型数据库。为了避免内容太过技术性,这里不会对图数据进行深入的介绍,只简单说下图数据库及关系型数据库的差别。
关系型数据库不擅长处理数据之间的关系,而图数据库在处理数据之间关系方面灵活且高性能。
传统的关系型数据库在处理复杂关系的数据上表现很差,这是因为关系型数据库是通过外键的约束来实现多表之间的关系引用的。查询实体之间的关系需要JOIN操作,而JOIN操作通常非常耗时。
而图数据库的原始设计动机,就是更好地描述实体之间的关系。图数据库与关系型数据库最大的不同就是免索引邻接,图数据模型中的每个节点都会维护与它相邻的节点关系,这就意味着查询时间与图的整体规模无关,只与每个节点的邻点数量有关,这使得图数据库在处理大量复杂关系时也能保持良好的性能。
另外,图的结构决定了其易于扩展的特性。我们不必在模型设计之初就把所有的细节都考虑到,因为在后续增加新的节点、新的关系、新的属性甚至新的标签都很容易,也不会破坏已有的查询和应用功能。
而关系型数据库,如果一开始就设计好数据字段并跑了一段时间数据,想再增加字段就会非常麻烦,需要开发人员或产品经理在开发初期就设想好未来可能会新增的字段,并提前加入到数据表中。
参考资料:
neo4j-图数据库
E-R图:实体与属性的划分原则
通俗易懂解释知识图谱(Knowledge Graph)
图数据库是什么?
作者:杨桃,游戏行业B端产品经理,爱用文字记录观察及想法。
本文由 @杨桃 原创发布于人人都是产品经理
马上咨询: 如果您有业务方面的问题或者需求,欢迎您咨询!我们带来的不仅仅是技术,还有行业经验积累。
QQ: 39764417/308460098 Phone: 13 9800 1 9844 / 135 6887 9550 联系人:石先生/雷先生