MNN-TaoAvatar开源
发布日期:2025/7/10 7:36:50 浏览量:
TaoAvatar 是由阿里巴巴淘天 Meta 技术团队研发的 3D 真人数字人技术,这一技术能在手机或 XR 设备上实现 3D 数字人的实时渲染以及 AI 对话的强大功能,为用户带来逼真的虚拟交互体验。TaoAvatar 基于先进的 3D 高斯泼溅技术,提供了一套全身互动式的真人数字人解决方案。它通过多视角视频的输入,可以迅速生成具有高逼真度的数字人形象,这些形象不仅能够精准地捕捉到细腻的面部表情和手势动作,甚至连衣物细微的褶皱以及头发的自然摆动都能清晰呈现,带来一种自然而真实的视觉体验。MNN-TaoAvatar 不仅能够在手机端流畅运行,还完美兼容了 XR 设备。
MNN-TaoAvatar 具有两个核心优势:端侧实时对话和端侧实时渲染。
端侧实时对话
首先,为了实现端侧的实时对话,需要将 ASR(自动语音识别)、TTS(文本转换语音)和 A2BS(口型驱动)的综合 RTF(Real Time Factor,实时因素)控制在 1 以内,即能在 1 秒内生成 1 秒长度的语音,RTF 值越小生成速度越快。通过持续优化,我们取得了以下突破:
为了让数字人的面部动作更为自然,渲染过程主要分为两个关键步骤:首先,根据语音输入,通过算法模型精准提取面部表情动作的系数,然后将表情系数和数字人 3D 模型的预录数据进行融合,最终借助 NNR 渲染器完成高质量渲染。这两部分我们做到的性能如下:
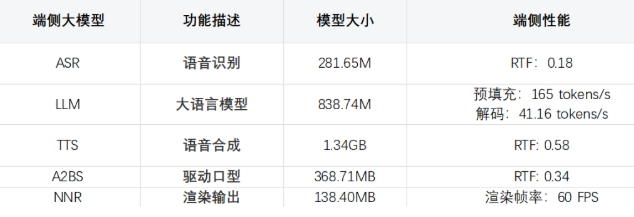
上文提及的具体端侧模型的功能及我们做到的技术指标如下(基于搭载高通骁龙 Snapdragon 8 Elite芯片的智能手机测试结果):
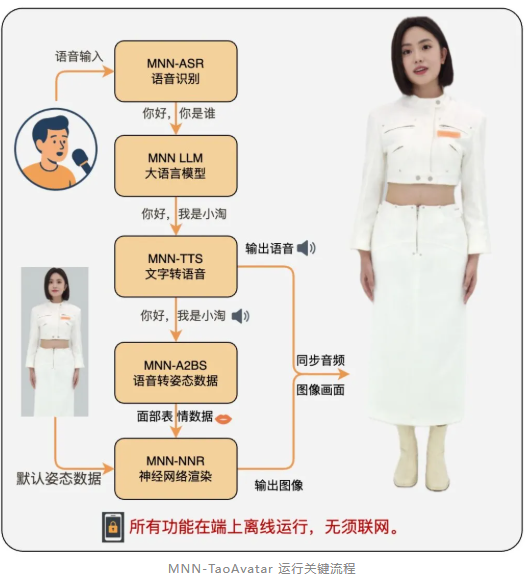
在用户尚未输入语音的情况下,MNN-TaoAvatar 会利用 MNN-NNR 来渲染默认的数字人模型姿态,生成闭唇、静态表情或者预设动作的画面。一旦用户开始语音输入,系统将按以下流程运行:
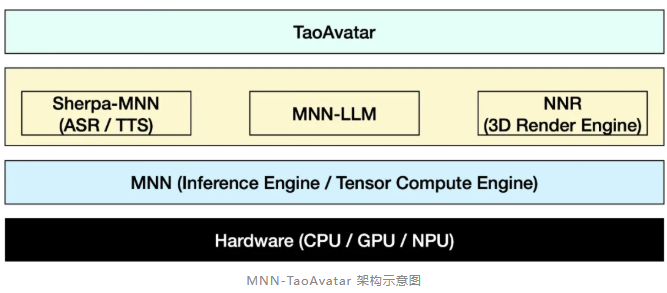
MNN-TaoAvatar 是基于 MNN 引擎构建而成的,它集成了 MNN-LLM、MNN-NNR 以及 Sherpa-MNN(包括 MNN-ASR 和 MNN-TTS)等多种算法模块。下图展示了这些模块在应用中的架构示意:
MNN(Mobile Neural Network)是一款功能强大的开源、跨平台 AI 模型推理引擎。
▐ MNN:轻量级 AI 推理引擎
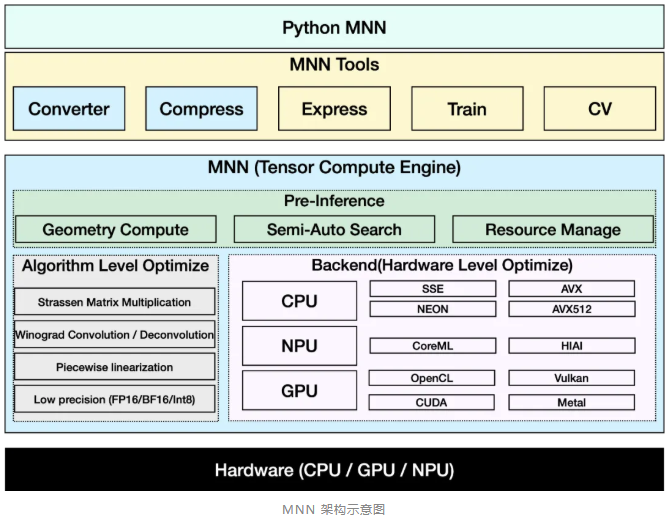
它的核心优势如下:
MNN-LLM 是基于 MNN 之上开发的 MNN-Transformer 模块的一个子功能模块,用于支持大语言模型与文生图等 AIGC 任务。它包含以下关键技术:
▐ MNN-LLM:移动端部署大模型
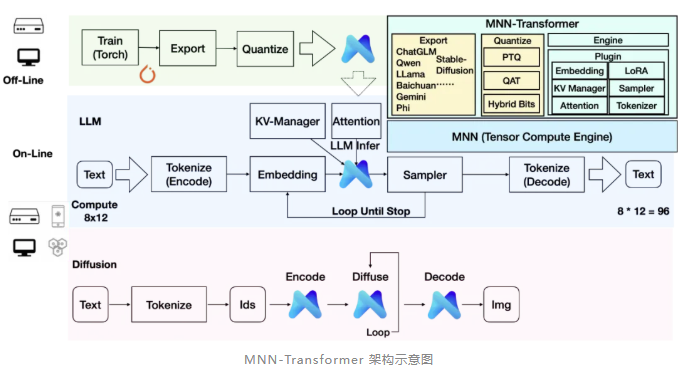
MNN-Transformer 由三个核心部分构成:导出工具、量化工具以及插件与引擎。
为提升语音识别在端侧上的表现,MNN 团队对原始 sherpa-onnx 框架进行了深度优化,推出 Sherpa-MNN,它支持 ASR(自动语音识别)和 TTS(文本转语音)算法,并具备如下优势:
性能翻倍:在 MacBook Pro M1 上(基于 arm64 架构),单线程运行经过量化处理的流式 ASR 模型(具体模型为 sherpa-onnx-streaming-zipformer-bilingual-zh-en-2023-02-20)。在这一测试中,onnxruntime 的 RTF(实时因子)为 0.078,而 MNN 的 RTF 仅为 0.035,相比于 onnxruntime 快出一倍。
MNN-NNR 是 TaoAvatar 的核心 3D 渲染引擎,专为在移动设备上实时渲染高质量数字人模型而设计。其核心的技术优势如下:
▐ Sherpa-MNN:离线语音智能新方案
▐ MNN-NNR:高效神经网络渲染引擎
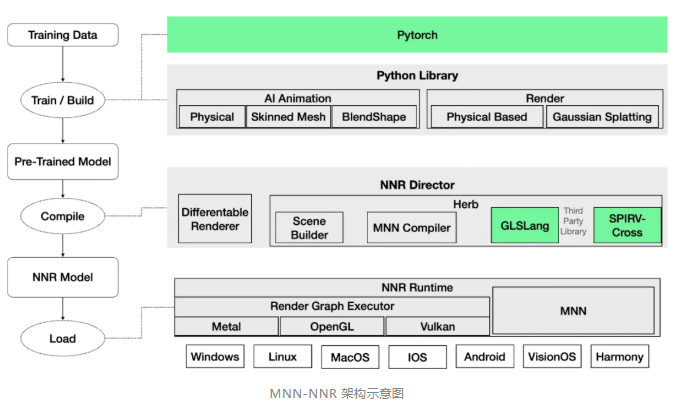
为了让数字人模型能够实现高效的渲染,我们进行了以下几项深度优化:
数据同步优化
在这些优化的加持下,MNN-NNR 成功实现了在动画模型仅以较低频率(如 20 fps)更新的情况下,画面依然能够以 60 fps 的流畅度进行输出。
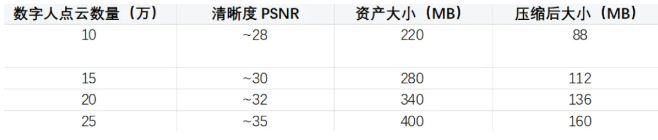
传统高斯点云重建成本高、存储体积大,而 TaoAvatar 采用了全新的多重优化方案:
通过相同素材重建得到的数字人模型,在不同高斯点云数量下,会呈现出不同的清晰度、模型体积和渲染性能。为了找到最佳的平衡点,我们进行了多种不同点云数量模型的测试:
为了消除数据同步所需的时间,我们让所有模型都在 MNN GPU 后端上运行,并在 NNR Runtime 中配置 MNN 所使用的 GPU 后端与渲染共享同一个上下文。这样,MNN Tensor 的数据就直接存储在 GPU 内存中。NNR Runtime 实现了直接读取 MNN Tensor GPU 内存的方案,无需进行数据拷贝即可直接用于渲染,从而免除了数据同步的时间。
在 NNR Runtime 中,我们实现了「Dirty 机制」,每一帧只运行输入数据发生变化的 MNN 模型。在 TaoAvatar 场景中,深度模型包括 Base Deformer、Aligner、Deformer、Color Compute 和 Sort 等。由于动态高斯数字人重建所需的图像是以 20 帧/秒的速度采集的,为了保持高斯数字人动作的平滑性和一致性,驱动高斯数字人动作的参数只需以 20 fps 的频率设置即可。
因此,Base Deformer、Aligner 和 Deformer 只需以 20 fps 的频率运行。在视角变化不大的情况下,也不需要每帧都对高斯点进行排序,所以 Sort 模型通过另一个开关来控制运行。这样,每帧实际运行的模型就只剩下 Color Compute,从而大幅降低了整体的运行时间。
对于使用 MNN 编译器的模型,将输入数据进行 fp16 压缩,可以提升 50% 的性能。
对于高斯排序,MNN 实现了基于 GPU 的基数排序算法,并且利用 autotuning 技术,确保在各类 GPU 上都能达到最佳性能。
▐ 3D 高斯数字人:小模型也能高质量
虽然我们已经进行了大量的优化工作,但由于需要将多个模型集成到手机中,所以对手机性能还是有一定要求的。以下是 MNN-TaoAvatar 的推荐配置:
⚠️ 性能不足的设备可能会遇到卡顿、声音断续或功能受限哦。
想要亲自体验一下吗?只需按照以下简单的步骤操作即可。
首先克隆项目代码:
然后构建并部署:
连接你的安卓手机,打开 Android Studio 点击「Run」,或执行:
通过这两个步骤,你就可以在自己的手机上体验 MNN-TaoAvatar 数字人应用了!
资源链接:
TaoAvatar Github 下载:https://github.com/alibaba/MNN/blob/master/apps/Android/MnnTaoAvatar/README_CN.md
TaoAvatar 论文:https://arxiv.org/html/2503.17032v1
MNN LLM论文:https://arxiv.org/abs/2506.10443
TaoAvatar模型合集:https://modelscope.cn/collections/TaoAvatar-68d8a46f2e554a
LLM模型:Qwen2.5-1.5B MNN:https://github.com/alibaba/MNN/tree/master/3rd_party/NNR
TTS模型:bert-vits2-MNN:https://modelscope.cn/models/MNN/bert-vits2-MNN
基础TTS模型:Bert-VITS2:https://github.com/fishaudio/Bert-VITS2
声音动作模型:UniTalker-MNN:https://modelscope.cn/models/MNN/UniTalker-MNN
基础声音动作模型:UniTalker:https://github.com/X-niper/UniTalker
神经渲染模型:TaoAvatar-NNR-MNN:https://modelscope.cn/models/MNN/TaoAvatar-NNR-MNN
ASR模型:Sherpa 双语流式识别模型:https://modelscope.cn/models/MNN/sherpa-mnn-streaming-zipformer-bilingual-zh-en-2023-02-20
china3dv live demo滑动可以看到 TaoAvatar:http://china3dv.csig.org.cn/LiveDemo.html
硬件要求
▐ 快速体验
git clone https://github.com/alibaba/MNN.gitcd apps/Android/Mnn3dAvatar
/gradlew installDebug
马上咨询: 如果您有业务方面的问题或者需求,欢迎您咨询!我们带来的不仅仅是技术,还有行业经验积累。
QQ: 39764417/308460098 Phone: 13 9800 1 9844 / 135 6887 9550 联系人:石先生/雷先生