腾讯开源数字人模型DICE- TALK,可以控制数字人的情绪了
发布日期:2025/5/25 18:56:44 浏览量:
DICE-Talk 的全称是“Disentangle Identity, Cooperate Emotion: Correlation-Aware Emotional Talking Portrait Generation”,其核心目标是解决当前情感化说话头像生成(Emotional Talking Head Generation, ETHG)领域的三大挑战:
- • 音频情感线索的利用不足:现有方法未能充分利用音频中固有的情感信息,导致生成的头像情感表达不够丰富。
- • 情感表示中的身份泄露:情感表示通常与说话者的身份耦合,这会导致生成的头像在身份一致性上出现问题。
- • 情感相关性学习的孤立性:现有方法未能有效捕捉不同情感之间的关系,生成的头像情感表达可能显得不自然。
为了应对这些挑战,DICE-Talk 提出一个新颖的框架,遵循“解耦身份,协作情感”的理念。具体而言:
- • 该项目通过联合建模音频和视觉情感线索,确保情感表达独立于身份。
- • 它引入了可学习的情感库(Emotion Banks),显式捕捉不同情感之间的相关性。
- • 通过潜在空间分类,确保扩散过程中的情感一致性。
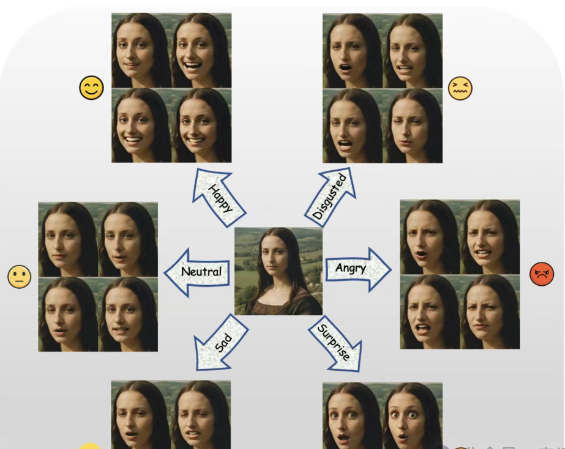
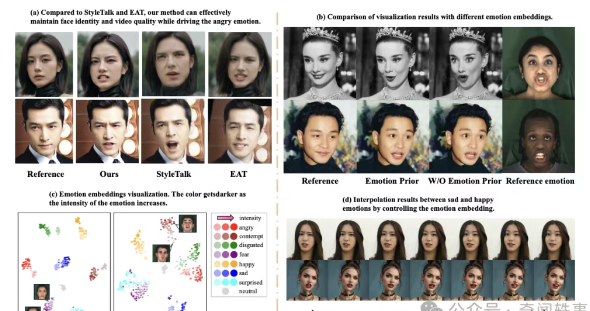
项目在 MEAD 和 HDTF 数据集上的实验结果表明,DICE-Talk 在情感准确性上超过了现有最先进的方法,同时保持了竞争性的唇同步性能。定性结果和用户研究进一步证实,该方法能够生成身份保持一致且情感丰富、相关性的头像,能够自然适应未见过的身份。
模型结构
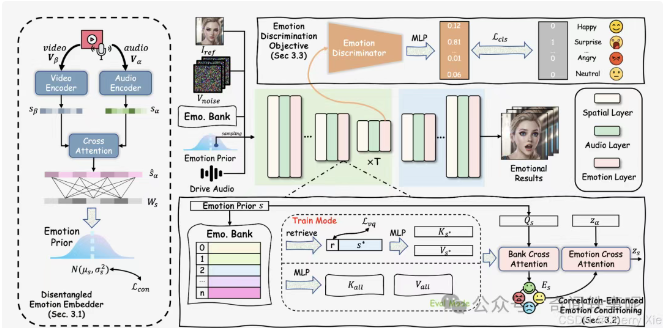
DICE-Talk 的模型结构设计精巧,旨在实现身份与情感的解耦以及情感之间的协作。以下是其主要组件的详细描述:
身份解耦的情感嵌入器(Disentangled Emotion Embedder)
• 功能:联合建模音频和视觉情感线索。
• 方法:使用跨模态注意力机制,将音频(例如语音信号)和视觉输入(例如面部图像)整合成情感表示。
• 特点:情感表示为与身份无关的高斯分布,确保生成的头像情感不受说话者身份的影响。
• 作用:通过解耦身份和情感,防止身份信息泄露到情感表示中,从而提高生成头像的通用性。
相关性增强的情感条件模块(Correlation-Enhanced Emotion Conditioning Module)
情感歧视目标(Emotion Discrimination Objective)

• 功能:确保扩散过程中的情感一致性。
• 方法:通过潜在空间分类,强制生成的头像在情感上与输入一致。这意味着在生成过程中,模型会持续检查生成的头像是否符合预期的情感表达。
• 特点:通过潜在空间分类,增强了生成头像的情感准确性,可能作为训练过程中的损失函数的一部分。
• 作用:提高生成结果的情感可信度,确保最终头像的情感表达与输入音频和视觉信息一致。
github地址:https://github.com/toto222/DICE-Talk
官方地址:https://toto222.github.io/DICE-Talk/
技术报告:https://arxiv.org/abs/2504.18087
马上咨询: 如果您有业务方面的问题或者需求,欢迎您咨询!我们带来的不仅仅是技术,还有行业经验积累。
QQ: 39764417/308460098 Phone: 13 9800 1 9844 / 135 6887 9550 联系人:石先生/雷先生