F5-TTS:上海交大开源超逼真声音克隆TTS,15秒即可克隆声音
发布日期:2024/11/15 23:16:40 浏览量:
F5-TTS是一款基于流匹配的全非自回归文本到语音转换系统,由上海交通大学、剑桥大学和吉利汽车研究院的研究团队联合开发。该系统无需复杂设计,如持续时间模型、文本编码器和音素对齐,能够实现快速训练,并达到RTF(实时因素)0.15的推理速度,明显优于当前基于扩散的TTS模型。
F5-TTS在公共的100K小时多语言数据集上进行训练,展现出高自然性和表现力的零样本能力、无缝代码切换能力和速度控制效率。项目提出了一种推理时的摇摆采样策略,显著提高了模型的性能和效率。
论文:https://arxiv.org/abs/2410.06885
模型下载:https://huggingface.co/SWivid/F5-TTS
Demo:https://huggingface.co/spaces/mrfakename/E2-F5-TTS
项目地址:https://github.com/SWivid/F5-TTS
模型特点
- 零样本 (Zero-shot) 声音克隆
- 速度控制(基于总时长)
- 可以控制合成语音的情感表现
- 长文本合成
- 支持中文和英文多语言合成
- 在 10 万小时数据上训练
- 最重要的是支持商用
技术优势
F5-TTS 独特的架构使得它与传统 TTS 系统相比更具优势:
- 并行处理:不像传统系统那样依赖逐步生成语音,F5-TTS 能够同时处理多个步骤,从而显著加快了生成速度。
- 多场景支持:无论是智能助手、在线教育、语音阅读器,还是其他需要 TTS 支持的场景,F5-TTS 都能够提供自然流畅的语音输出。
- 大规模数据训练:F5-TTS 在超过 100K 小时的多语言数据集上进行训练,这让它能够在不同语言和语境下提供卓越的语音生成能力。
可移步语音之家其他平台听取音频
使用方法
1、自定义本地部署服务
本地部署,需要保证GPU资源(算力)充足及Python环境。
- 克隆项目
git clone https://github.com/SWivid/F5-TTS.git
- 安装项目依赖包
pip install -r requirements.txt
- 安装合适的CUDA包(英伟达显卡必须)
pip install torch==2.3.0+cu118 --extra-index-url https://download.pytorch.org/whl/cu118
- 准备数据集并训练、推理、运行项目
python gradio_app.py
2、在线使用
通过官网直接体验其多语言语音生成和速度、情感控制功能。
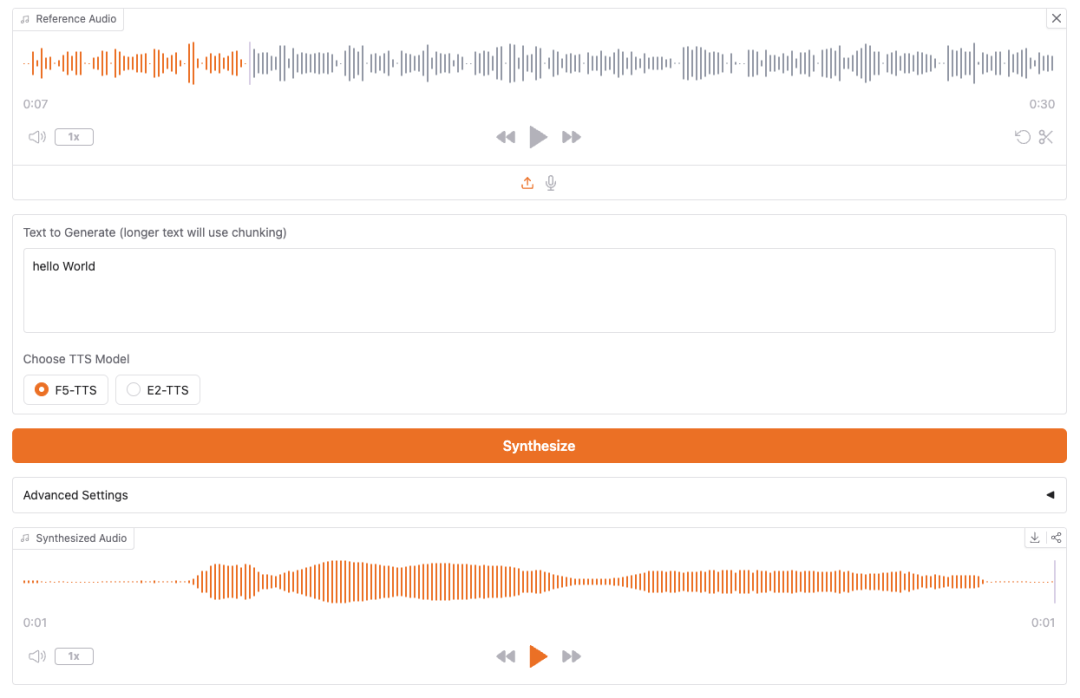
- 上传原始音色音频,最好是说话的音频,也可以录制自己的声音上传。
- 然后输入需要转成语音的文本。
- 同步生成,最后就可生成带预期音色的音频了。
总结
F5-TTS 是继Chat-TTS后有一款强大的TTS开源工具,尤其是在多语言处理、情感表达和语音生成速度上都实现了突破。
资源下载地址:
最新AI语音大模型,本地一键部署整合包,完美复刻语气音色,支持多角色对话,解压即用,AI语音克隆。
[原项目GitHub地址]:https://github.com/jpgallegoar/F5-TTS
整合包聚合链接:https://exmzfs7zve.feishu.cn/docx/FuPxdArRaofVMWxke2tc8IO9nCh?from=from_copylink
夸克网盘链接:https://pan.quark.cn/s/a0d2ebe90488 提取码:nmgV
百度网盘链接: https://pan.baidu.com/s/1m3G34q9R3IvUII2rsfjzEg?pwd=tfe8 提取码: tfe8
马上咨询: 如果您有业务方面的问题或者需求,欢迎您咨询!我们带来的不仅仅是技术,还有行业经验积累。
QQ: 39764417/308460098 Phone: 13 9800 1 9844 / 135 6887 9550 联系人:石先生/雷先生