YOLO算法讲解
发布日期:2022/6/18 6:47:39 浏览量:
YOLO 是 2016 年提出来的目标检测算法,在当时比较优秀的目标检测算法有 R-CNN、Fast R-CNN 等等,但 YOLO 算法还是让人感到很新奇与兴奋。
YOLO 是 You only look once 几个单词的缩写,大意是你看一次就可以预测了,灵感就来自于我们人类自己,因为人看一张图片时,扫一眼就可以得知这张图片不同类型目标的位置。
YOLO 胜在它的简单与快速。
YOLO 是单个神经网络进行端到端的预测,没有多个步骤和过程。
YOLO 的速度非常快,可以达到实时的 45 fps,简化版本甚至达到 155 fps。
YOLO 目标预测如同捕鱼
在 YOLO 前,目标检测一般通过算法生成候选区域,然后在数量众多的候选区域中做目标的分类和 bbox 位置的回归。
更古老的方法是通过滑动窗口的形式去挨个预测与判别。
但 YOLO 大不相同。
如果把目标检测看做是一个捕鱼的过程,其他算法是拿着渔叉一个一个精准地狙击,那么 YOLO 就粗犷的多,一个渔网撒撒下去,一网打尽。
YOLO 的预测是基于整个图片的,并且它会一次性输出所有检测到的目标信息,包括类别和位置。
YOLO 的算法思路。

缩放输入的图片
将图片送入到卷积神经网络中进行预测
通过预测的结果进行置信度的阈值处理,得到最终的结果。
下面讲解算法细节。
分割图片
YOLO 会把输入图片分割成 SxS 个网格,如果一个目标的中心点落在某个网格当中,那么对应的那个网格就负责预测这个目标的大小和类别。

上面的图片示例中,狗的中心点落在了蓝色的网格当中,所以蓝色的网格就负责这个目标的信息预测。
每个网格目标的预测
每个网格都会预测 B 个 bbox 和 bbox 对应的置信值 Confidence,bbox 预测目标的位置,Confidence 用来反映这个网格是否有包含目标及 bbox 的准确性有多高。

这样的结果是针对每一个 bbox 而言的目标类别概率分布的置信值,这个置信值同时表达了 2 样东西,一个是目标是某个类别的概率,一个是预测的 bbox 离真实的 bbox 有多远。
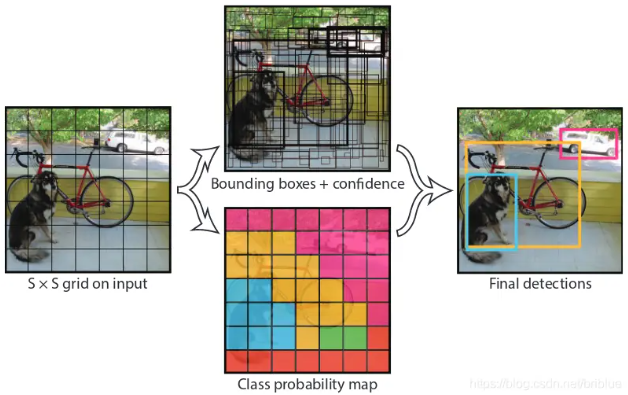
YOLO 把输入图片划分成 SxS 个网格,每个网格都会预测 B 个 bbox 和 C 个目标类别的条件概率,并且每一个 bbox 包含 x、y、w、h、confidence 5 个参数。
所以,YOLO 最终的预测结果可以整合成一个尺寸为 SS(5*B+C) 的 tensor。
B、S、C 这几个值都由网络结构的设计者决定,YOLO v1 在 PASCAL VOC 数据集上评估时,S = 7,B = 2。
因为这个数据集有 20 个种类,所以 C = 20,套用前面的公式,最终预测时 Tensor 的尺寸为 7730。
YOLO 的网络结构设计
YOLO 是基于 CNN 的,论文作者说他受 GooLeNet 结构的启发,然后构建了一个新的网络结构。
YOLO 用 1x1 的卷积核代替了 GooLeNet 的 Inception 模块来做降维度。
YOLO 有 24 个卷积层,然后后面跟着 2 个全连接层。
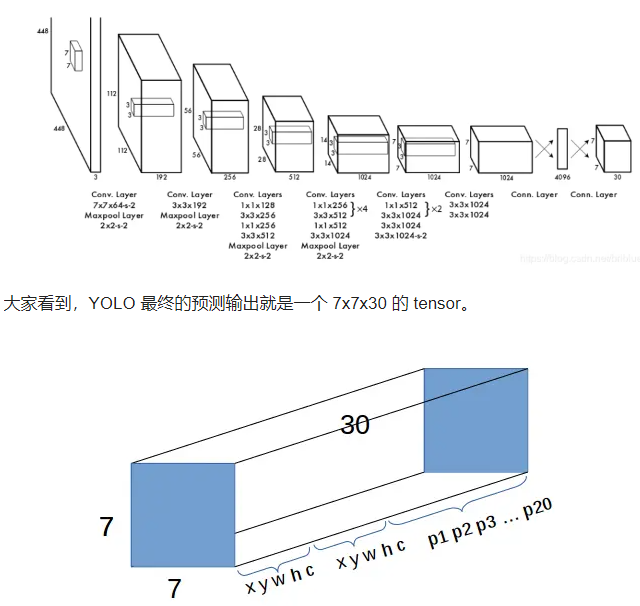
这张图片也可以大致示意最终预测的 tensor 的结构。
YOLO 的训练过程
YOLO 在 ImageNet 上用前 20 个卷积层和 1 个全连接层做通用的类别识别训练,并达到比较高的准确率。
之后,YOLO 作者在预训练好的结构上添加了 4 个卷积层和 1 个全连接层做目标识别训练。
因为想提高目标识别的整体表现,所以 YOLO 在 ImageNet 预训练时,输入图片尺寸是 224x224,但在 PASCAL VOC 上做目标识别的专项训练时,输入图片尺寸变成了 448x448
除了最后一层采用线性激活函数外,其他层都采用 leaky Relu。
YOLO 的 Loss 设定
我们都知道,采用合适的 loss 对于训练一个神经网络而言非常重要。
而我认为,只有理解了 YOLO 的 loss 设计原则,才算真正理解了 YOLO 算法的核心.
我们知道,一般 Loss 值越低,代表网络准确度越高,训练的越有效,所以训练时基本上是以减弱 loss 值为目标的。
YOLO 作者在训练时,用 sum-squared error (误差的平方的和)来作为 loss 进行优化。
采用 sum-squared error 是因为它容易进行优化,但是它也有不好的地方,那就是对于提高 mAP 的表现有些吃力。
sum-squared error 会让 Loss 函数对于位置预测、类别预测的误差权重一样。
实际情况是,YOLO 在每一张图片上会预测 772=98 个 bbox,但只有很少的 bbox 才包含目标,哪些不包含目标的 bbox 它们的 confidence 会在训练过程中很快变成 0,所以哪些包含了目标的网格它们预测的 bbox 的梯度会更加急剧变化,这样而言,整个预测系统处于不平衡也不稳定的状态,最终可能出现 loss 无法收敛。
为了,纠正和改善情况,YOLO 的作者调整了 bbox 的坐标误差和 没有包含目标时 confidence 的误差权重,也可以看做是添加了不同的惩罚系数,分别是 5 和 0.5。
为什么这样做呢?
可以这样理解,整个 YOLO 系统其实最有效的地方就是那些包含了目标中心点的网格它们所预测的 2 个 bbox,所以它们这 2 个 bbox 的位置信息就至关重要,所以它们的坐标就不允许它们变化剧烈,所以就需要添加一个系数放大它们的误差,进而达到惩罚的目的。
而没有包含目标的网格,虽然它们也会预测 bbox,也会有 confidence 的预测,但基本等同于无效,所以可以看做它们对于整体的 Loss 而言,没有那么重要,因此要减弱它们对于 Loss 的影响,以防止它去干扰正常的包含了目标的那些 bbox 的 confidence 表现,毕竟它无关紧要。
说到这里,我有思考一个问题:
如果要减弱没有 object 时的 confidence 对 loss 整体的影响,为什么不做到极致?让惩罚系数由 0.5 变成 0 不更好吗?
我没有标准答案,但我的理解是那样会让 YOLO 这个系统失衡,丧失了预测背景的能力,所以也失去了某种综合的能力。
sum-squared error 还有一个问题,那就是它会让大的 bbox 和小的 bbox 位置误差敏感度一样。
比如预测一个小的 bbox,groundtruth 的 width 是 4,它预测是 3,那么它的误差是 1.
再预测一个大的 bbox,groundtruth 的 width 是 100,预测值是 99,那么误差也是 1.
但大家很容易发现,进行小尺寸的 bbox 预测时,误差更敏感,所以 sum-sqaured error 手段需要改良。
YOLO 采用的是用预测值和 groundtruth 各自的平方根做误差,然后再 sum-sqaured error。
还是用刚才的例子,小的 bbox width prediction = 3,groundtruth = 4,误差为 0.067。
大的 bbox width prediction = 99,groundtruth = 100,误差为 0.0025。
所以,完美的解决了这个问题。
最终的 Loss 变成了一个复合的 Loss,公式如下:
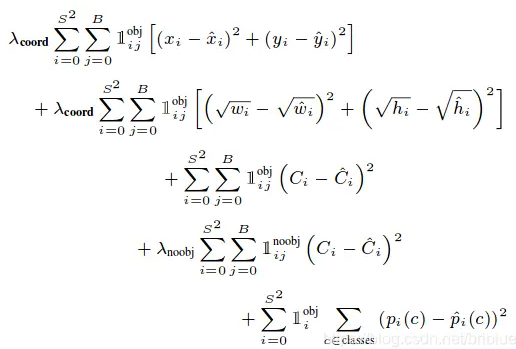
需要注意的是,YOLO 每个网格预测两个 bbox,最终只有 1 个 bbox 来负责代表相应的目标的 bbox 位置,它们通过 Confidence 比较,也就是 IOU 比较,胜出的是分数更高的那个,进行 loss 计算时,也是这个 bbox 才能参与。
其它具体的训练策略如下:
第一个 epoch,学习率从 0.001 缓慢变成 0.01.
接下来的 75 个 epoch ,学习率固定为 0.01
之后又用 0.001 训练 30 个 epoch
最后用 0.0001 训练 40 个 epoch
为了避免过拟合,YOLO 训练时有采用 dropout 和数据增强手段。
总结
YOLO v1 也有和当年其它杰出的目标检测系统做对比,但在今天来看,这个并不十分重要,重要的是我们需要理解 YOLO 快的原因。
YOLO 就是一个撒渔网的捕鱼过程,一次性搞定所有的目标定位。
YOLO 快的原因在于比较粗的粒度将输入图片划分网格,然后做预测。
YOLO 的算法精髓都体现在它的 Loss 设计上及作者如何针对问题改进 Loss,这种思考问题的方式才是最值得我们学习的。
马上咨询: 如果您有业务方面的问题或者需求,欢迎您咨询!我们带来的不仅仅是技术,还有行业经验积累。
QQ: 39764417/308460098 Phone: 13 9800 1 9844 / 135 6887 9550 联系人:石先生/雷先生